본 게시물은 트래블록스 프로젝트를 진행하며 발생한 문제 및 개선 사항을 정리한 글입니다.
배경
초기 알림 테이블(notifications)에는 별도의 인덱스가 없이 설계되었지만,
대용량 환경을 대비해 안정적인 성능을 유지할 수 있도록 최적화가 필요하다고 판단했다.
따라서 1차적으로는 복합 인덱스를 통해, 2차적으로는 Covering Index 전략을 이용해 조회 성능을 최적화하려 했다.
커서 기반 페이징을 이용했기에 사용한 SQL문은 아래와 같았다.
SELECT notification_id, created_at, actor_id, actor_nickname_snapshot, receiver_id, template_id, type
FROM notifications
WHERE receiver_id = 1
AND created_at < NOW(6) - INTERVAL 30 DAY
ORDER BY created_at DESC, notification_id DESC
LIMIT 10;
대용량 데이터 삽입
실제 운영 환경을 가정하여 40만 건의 더미 데이터를 아래 SQL문을 통해 삽입해주었다.
SET autocommit = 0;
INSERT INTO notifications (
created_at, actor_id, actor_nickname_snapshot, receiver_id, template_id, type
)
SELECT
NOW(6) - INTERVAL FLOOR(RAND() * 365) DAY
- INTERVAL FLOOR(RAND() * 86400) SECOND,
FLOOR(1 + RAND() * 3),
ELT(FLOOR(1 + RAND() * 3), '판당이', '효미', '조아'),
CASE
WHEN RAND() < 0.7 THEN 1
WHEN RAND() < 0.9 THEN 2
ELSE 3
END,
FLOOR(1 + RAND() * 100000),
ELT(FLOOR(1 + RAND() * 2), 'TEMPLATE_FAVORITED', 'TEMPLATE_REMIXED')
FROM information_schema.columns a
CROSS JOIN information_schema.columns b
LIMIT 400000;
COMMIT;
SET autocommit = 1;
데이터 수 확인하기
SQL문을 활용하여 40만개의 데이터 수를 확인했다.
SELECT COUNT(*) AS cnt FROM notifications;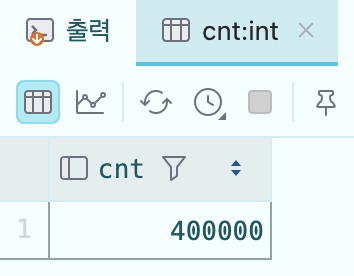
조회 성능 비교
[기존] 인덱스 미적용 상태의 실행
EXPLAIN ANALYZE
SELECT notification_id, created_at, actor_id, actor_nickname_snapshot, receiver_id, template_id, type
FROM notifications
WHERE receiver_id = 1
AND created_at < NOW(6) - INTERVAL 30 DAY
ORDER BY created_at DESC, notification_id DESC
LIMIT 10;
EXPLAIN ANALYZE를 확인해 실제 측정값을 확인해보았다.
평균값을 내기 위해 총 5번 실행을 해주었으며, 첫 시도는 제외했다.





결과
- Full Table Scan 발생 (약 40만 건 전체 탐색)
- 필터링 후 약 26만 건 정렬 수행 (매우 큰 정렬 비용, 실행 시간의 대부분이 정렬 비용)
- 평균 DB 내부 실행 시간 181.6ms
원인
- WHERE과 ORDER BY를 동시에 만족하는 복합 인덱스의 부재
- 대량의 정렬 비용 발생
- LIMIT가 있지만 전부 수행되는 정렬
[1차 개선] 복합 인덱스 설계 -> '정렬 제거'에 집중
아래와 같이 WHERE과 ORDER BY를 동시에 만족하도록 복합 인덱스를 설계해주었다.
CREATE INDEX idx_notifications_receiver_created_id
ON notifications (receiver_id, created_at DESC, notification_id DESC);
SELECT문은 위에서와 같이 실행해주었다.
EXPLAIN ANALYZE
SELECT notification_id, created_at, actor_id, actor_nickname_snapshot, receiver_id, template_id, type
FROM notifications
WHERE receiver_id = 1
AND created_at < NOW(6) - INTERVAL 30 DAY
ORDER BY created_at DESC, notification_id DESC
LIMIT 10;
마찬가지로 EXPLAIN ANALYZE를 확인해 실제 측정값을 확인해보았다.
평균값을 내기 위해 총 5번 실행을 해주었으며, 첫 시도는 제외했다.





결과
- Full Scan 제거
- Filesort 제거
- Index range scan 적용
- 평균 DB 내부 실행 시간 5.064ms
[2차 개선] Covering Index + PK Lookup -> '접근 구조'에 집중
1차 개선을 통해서도 약 36배의 성능 향상(97% 단축)이 있었지만,
1차 개선에서는 쿼리에 필요한 모든 컬럼을 인덱스가 포함하는 것은 아니어서 1) Index 탐색 2) PK 조회 3) 테이블 접근(랜덤 I/O) 의 단계를 거치는데, Covering Index를 통해 랜덤 I/O를 제거하고, 디스크 접근을 최소화하고자 했다.
EXPLAIN ANALYZE
SELECT n.notification_id, n.created_at, n.actor_id,
n.actor_nickname_snapshot, n.receiver_id,
n.template_id, n.type
FROM notifications n
JOIN (
SELECT notification_id
FROM notifications
WHERE receiver_id = 1 AND created_at < NOW(6) - INTERVAL 30 DAY
ORDER BY created_at DESC, notification_id DESC
LIMIT 10
) as temp ON n.notification_id = temp.notification_id;
위와 같이 쿼리를 개선함에 따라
서브쿼리에서는 인덱스만 사용해서 notification_id만 추출하고 테이블 접근이 없고(Covering Index)
이후 PK lookup을 10회 수행하게 된다.
여기서 Covering Index에 대해 조금 더 설명하자면,
쿼리에 필요한 모든 컬럼을 인덱스가 포함하고 있어 테이블에 다시 접근하지 않아도 되는 인덱스를 의미한다.





결과
- 테이블 접근 최소화
- 평균 DB 내부 실행 시간 1.0584ms
1차 개선 VS 2차 개선
InnoDB에서 Secondary Index 리프에는 '인덱스 컬럼 + PK'만 저장되기 때문에 실제 row 데이터는 PK를 통해 다시 읽어야 한다.
1차 개선에서는 인덱스에 있는 컬럼 이외에도 조회해야하는 데이터가 있기 때문에 PK로 row마다 테이블에 접근해야 해서 I/O가 생기게 된다.
하지만 2차 개선의 서브 쿼리에는 인덱스 안에 필요한 컬럼이 있기 때문에 서브 쿼리 내에서는 테이블 접근이 없고, 외부 JOIN에서만 PK로 테이블에 10번 접근하기 때문에 더 좋은 성능을 갖게 된다.
| 단위 (ms) | 개선 전 | 1차 개선 | 2차 개선 | 실행시간 개선율 |
| 1 | 181 | 7.63 | 1.21 | 99.3% |
| 2 | 178 | 5.35 | 1.42 | 99.2% |
| 3 | 179 | 4 | 0.875 | 99.5% |
| 4 | 189 | 5.56 | 1.17 | 99.4% |
| 5 | 181 | 2.78 | 0.617 | 99.7% |
| 평균 | 181.6 | 5.064 | 1.0584 | 99.4% |
(단위: ms)
삽입 성능 비교
조회 최적화를 위해 보조 인덱스를 도입했고, 조회 성능은 약 99.4%가 향상되는 효과가 있었다.
하지만, 인덱스를 하나 추가 하게 되면, row를 하나 삽입할 때 인덱스 개수만큼 B+Tree에 삽입이 발생하게 된다. (O(log N))
하지만 O(log N)보다 체감이 더 클 수도 있는데,
그 이유는 B+Tree 리프 페이지가 16KB이기 때문에 새 데이터가 들어왔을 때 해당 페이지에 공간이 없으면 페이지 분할이 발생하기 때문이다.
위에서 보조인덱스를 1개 추가해주었는데, 삽입 성능도 측정해볼 필요성을 느껴 측정해보았다.
기존의 40만개의 데이터에 추가로 20만개의 데이터를 넣어주었다.
[기존] 인덱스 미적용 상태의 실행
아래는 인덱스가 없을 때의 실행 결과로, 평균값을 내기 위해 총 5번 실행을 해주었으며, 첫 시도는 제외했다.





결과
- 평균 DB 내부 실행 시간 2826.4ms
[1차 개선] 복합 인덱스 설계
아래는 인덱스가 있을 때의 실행 결과로, 평균값을 내기 위해 총 5번 실행을 해주었으며, 첫 시도는 제외했다.





결과
- 평균 DB 내부 실행 시간 3720.8ms
| 인덱스 X | 인덱스 O | INSERT 수행 시간 증가율 | |
| 1 | 3042 | 3602 | 18.4% |
| 2 | 2827 | 3809 | 34.7% |
| 3 | 2881 | 3864 | 34.1% |
| 4 | 2668 | 3947 | 47.9% |
| 5 | 2729 | 3382 | 23.9% |
| 평균 | 2826.4 | 3720.8 | 31.7% |
(단위: ms)
위의 결과를 통해 보조 인덱스를 추가함에 따라 조회 성능은 증가하였지만, 쓰기 성능은 감소한 것을 확인할 수 있다.
결론적으로, 알림은 현재 읽기 빈도가 쓰기 빈도가 훨씬 크다고 판단했고, 읽기 성능이 전체 시스템 성능에 더 중요하다고 판단해 인덱스를 도입하기로 결정했다.
물론 쓰기 성능이 훨씬 중요한 기능에서는 아무리 조회 성능이 좋아졌다고 해서 그에 따른 쓰기 성능이 감소할 것이기 때문에 다른 결정을 내려야 할 수도 있다. 읽기 성능, 쓰기 성능의 트레이드 오프를 고려하여 기능에 적절한 최적화 방식을 선택해야함을 다시금 깨달았다.
'projects > travlocks' 카테고리의 다른 글
| [트러블슈팅] Redis 캐시 조회 시 Invalid UTF-32 character 발생 문제 해결 (0) | 2026.01.29 |
|---|