그래프 탐색 문제를 풀어보다 접한 문제이다.
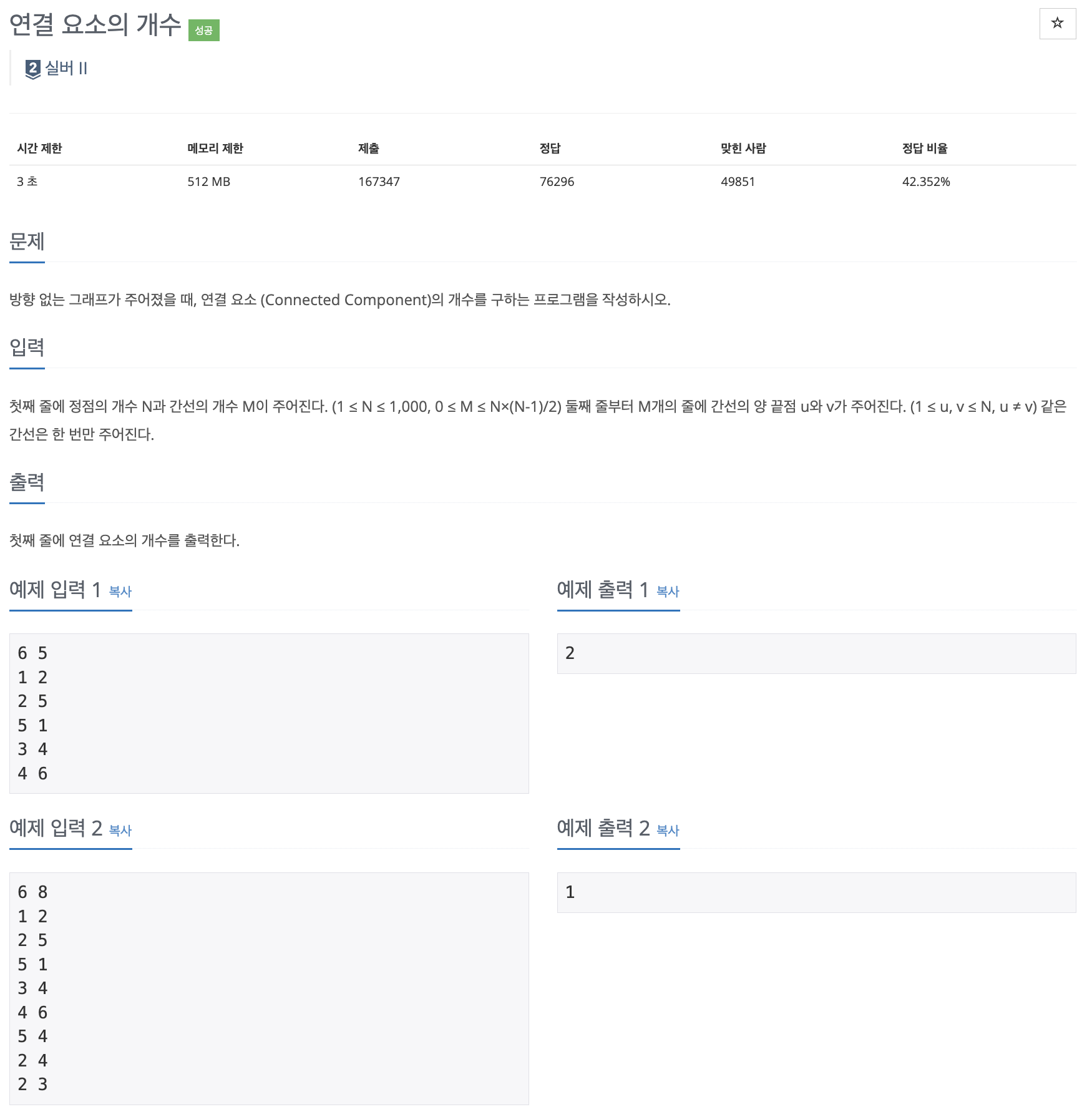
import java.util.*;
import java.io.*;
public class Main {
static ArrayList<Integer>[] adjList;
static boolean[] isVisited;
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
StringTokenizer st = new StringTokenizer(br.readLine(), " ");
int N = Integer.parseInt(st.nextToken());
int M = Integer.parseInt(st.nextToken());
isVisited = new boolean[N + 1];
int node1, node2, count = 0;
// 인접리스트 만들기
adjList = new ArrayList[N + 1];
for (int i = 1; i <= N; i++) {
adjList[i] = new ArrayList<>();
}
// 인접리스트에 그래프 넣기
for (int i = 1; i <= M; i++) {
st = new StringTokenizer(br.readLine(), " ");
node1 = Integer.parseInt(st.nextToken());
node2 = Integer.parseInt(st.nextToken());
adjList[node1].add(node2);
adjList[node2].add(node1);
}
// 탐색
for (int i = 1; i <= N; i++) {
// 이미 방문한 노드라면 패스
if (isVisited[i]) continue;
count++;
dfs(i);
}
System.out.println(count);
}
public static void dfs(int start) {
isVisited[start] = true;
for (int n : adjList[start]) {
if (isVisited[n]) continue;
dfs(n);
}
}
}위에 있는 코드는 내가 푼 풀이이다.
한창 DFS, BFS 문제를 풀고 있어서 그렇게 풀었는데,
생각보다 시간이 엄청 오래 걸렸고, 나처럼 DFS로 풀면 오래 걸리는 것 같다. (무려 600ms가 걸렸다.)
다른 사람의 코드를 살펴보다 Union-Find 알고리즘을 발견하게 되어 정리해본다.
Union-Find(Disjoint Set Union)
간략하게 말하면 노드들이 몇 개의 그룹(집합)으로 나뉘는지를 계산한다. (서로소 집합 구조 이용)
크게 union(a, b) 과 find(a)로 구성되어 있다.
| 연산 | 설명 |
| union(a, b) - a와 b는 노드 | a와 b가 속한 집합을 하나로 합친다. |
| find(a) - a는 노드 | a가 속한 집합의 대표 노드를 반환한다. |
| parent[] | 대표 노드를 저장하는 배열. 처음에는 자기 자신이 대표(parent[i] = i)이고, union을 하면서 대표를 바꿔준다. |
// union 함수
static void union(int a, int b) {
// 각 노드가 포함된 집합의 대표 노드 찾기
int rootA = find(a);
int rootB = find(b);
// 같은 집합에 속하는지 체크하고, 다른 집합에 속한다면 합쳐준다. (b 집합의 대표 노드를 a 집합의 대표 노드로)
if (rootA != rootB) {
parent[rootB] = rootA;
}
}// find 함수 (자신이 속한 집합의 대표 노드를 찾는 연산)
static int find(int x) {
// parent 배열의 index값과 value값이 같은지 체크
if (parent[x] != x) {
parent[x] = find(parent[x]); // 경로 압축을 통해 x의 대표 노드를 변경
}
return parent[x];
}
find 함수에서 재귀 호출(경로 압축)이 있는 이유는,
현재 아래와 같이 연결된 그래프가 있다고 생각해보자.
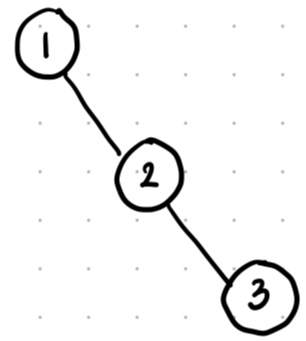
맨 처음에 집합의 대표 노드를 저장하는 parent 배열은 자기 자신이 저장되어 있을 것이다.
1, 2, 3 세 노드는 같은 집합에 속해있기 때문에
union(1, 2), union(2, 3) 이후에는 parent의 모든 곳에 1이 저장되어 있어야 한다. (1을 대표노드라고 가정)
union(1, 2)의 경우 경로 압축을 하지 않으니 parent[2]에 1이 저장됨은 쉽게 알 수 있다.
union(2, 3)의 경우에는, 3이 속한 집합의 대표 노드는 1이므로 parent[3]도 1이 저장되야 하지만,
노드 1과 노드 3은 직접적으로 연결돼 있지 않고, 우리는 2의 대표 노드를 찾아서 parent[3]에 1을 넣어줘야 한다.
이때 2의 대표 노드를 찾아야 하니까 재귀 호출로 find()가 또 호출되는 것이다.
즉, 말이 경로 압축이라 해서 어렵게 느껴졌던 거지, 간단하게 말하면 그냥 집합의 대표 노드를 parent에 업데이트 해준다고 생각하면 된다.

위의 문제에 적용해서 코드를 작성해보면 아래와 같다.
import java.io.*;
import java.util.*;
public class Main {
static int[] parent;
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
StringTokenizer st = new StringTokenizer(br.readLine());
int n = Integer.parseInt(st.nextToken()); // 정점 수
int m = Integer.parseInt(st.nextToken()); // 간선 수
parent = new int[n + 1];
for (int i = 1; i <= n; i++) {
parent[i] = i; // 자기 자신을 대표로 초기화
}
// 간선 입력 받아 union 수행
for (int i = 0; i < m; i++) {
st = new StringTokenizer(br.readLine());
int u = Integer.parseInt(st.nextToken());
int v = Integer.parseInt(st.nextToken());
union(u, v);
}
// 대표 노드 정리
for (int i = 1; i <= n; i++) {
find(i); // 경로 압축
}
// 대표 노드 개수 세기 (중복 없도록 대표 노드 수 계산)
Set<Integer> set = new HashSet<>();
for (int i = 1; i <= n; i++) {
set.add(parent[i]);
}
System.out.println(set.size());
}
static int find(int x) {
if (parent[x] != x) {
parent[x] = find(parent[x]); // 경로 압축
}
return parent[x];
}
static void union(int a, int b) {
int rootA = find(a);
int rootB = find(b);
if (rootA != rootB) {
parent[rootB] = rootA; // 한쪽을 다른 쪽에 붙이기
}
}
}'코딩테스트 > 백준' 카테고리의 다른 글
| [백준] #11497 통나무 건너뛰기, 그리디 (0) | 2026.03.10 |
|---|---|
| [백준] #2156 포도주 시식, DP (3) | 2025.08.25 |
| [백준] #1463 1로 만들기 (6) | 2025.08.12 |
| [백준] #4195 친구 네트워크, Map과 HashMap, Arrays.fill() (2) | 2025.08.07 |
| [백준] #1260 DFS와 BFS (0) | 2025.08.03 |